As you may know we have been working on bringing Mono to the
WebAssembly platform.
As part of the effort we have been pursuing two strategies; one that
uses the new Mono IL interpreter to run managed code at runtime, and
one that uses full static (AOT) compilation to create one .wasm file
that can be executed natively by the browser.
We intend the former to be used for quickly reloading C# code and prototyping and the latter for publishing your final application, with all the optimizations enabled. The interpreter work has now been integrated into Mono’s source code and we are using it to develop, port and tune the managed libraries to work on WebAssembly.
This post is about the progress that we have been making on doing static compilation of .NET code to run on WebAssembly.

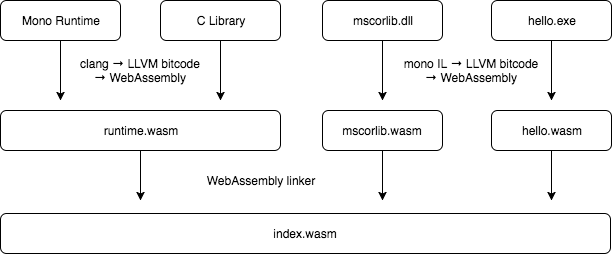
WebAssembly static compilation in Mono is orchestrated with the
mono-wasm command-line tool. This program takes IL assemblies as
input and generates a series of files in an output directory, notably
an index.wasm file containing the WebAssembly code for your
assemblies as well as all other dependencies (the Mono runtime, the C
library and the mscorlib.dll library).
$ cat hello.cs
class Hello {
static int Main(string[] args) {
System.Console.WriteLine("hello world!");
return 0;
}
}
$ mcs -nostdlib -noconfig -r:../../dist/lib/mscorlib.dll hello.cs -out:hello.exe
$ mono-wasm -i hello.exe -o output
$ ls output
hello.exe index.html index.js index.wasm mscorlib.dll
mono-wasm uses a version of the Mono compiler that, given C#
assemblies, generates LLVM bitcode suitable to be passed to the LLVM
WebAssembly backend. Similarly, we have been building the Mono runtime
and a C library with a version of clang that also generates LLVM
WebAssembly bitcode.
Until recently, mono-wasm was linking all the bitcode into a single
LLVM module then performing the WebAssembly code generation on
it. While this created a functional .wasm file, this had the
downside of taking a significant amount of time (half a minute on a
recent MacBook Pro) every time we were building a project as a lot of
code was in play. Some of the code, the runtime bits and the
mscorlib.dll library, never changed and yet were still being
processed for WebAssembly code generation every time.
We were thrilled to hear in late November of last year that the LLVM
linker (lld) was getting WebAssembly
support.
Since then, we changed our mono-wasm tool to perform incremental
compilation of project dependencies into separate .wasm files, and
we integrated lld’s new WebAssembly driver in the tool. Thanks to
this approach, we now perform WebAssembly code generation only when
required, and in our testing builds now complete in less than a second
once the dependencies (runtime bits and mscorlib.dll) have already
been compiled into WebAssembly.
Additionally, mono-wasm used to use the LLVM WebAssembly target to
create source files that would then be passed to the
Binaryen toolchain to
create the .wasm code. We have been testing the backend’s ability
to generate .wasm object files directly (with the
wasm32-unknown-unknown-wasm triple) and so far it seems promising
enough that we changed mono-wasm accordingly. We also noticed a
slight decrease in build time.
| Old toolchain | New toolchain (First Compile) | New toolchain (Rebuild) | |
|---|---|---|---|
| Full application build | ~40s | ~30s | <1s |
| Hello World program | ~40s | <1s | <1s |
There is still a lot of work to do on bringing C# to WebAssembly, but we are happy with this new approach and the progresses we are making. Feel free to watch this space for further updates. You can also track the work on the mono-wasm GitHub repository.
For those of you that want to take this for a spin you can download a preview release, unzip and run “make” in the samples. This currently requires MacOS High Sierra to run.