Up to now, Linux packages on mono-project.com have come in two flavours – RPM built for CentOS 7 (and RHEL 7), and .deb built for Debian 7. Universal packages that work on the named distributions, and anything newer.
Except that’s not entirely true.
Firstly, there have been “compatibility repositories” users need to add, to deal with ABI changes in libtiff, libjpeg, and Apache, since Debian 7. Then there’s the packages for ARM64 and PPC64el – neither of those architectures is available in Debian 7, so they’re published in the Debian 7 repo but actually built on Debian 8.
A large reason for this is difficulty in our package publishing pipeline – apt only allows one version-architecture mix in the repository at once, so I can’t have, say, 4.8.0.520-0xamarin1 built on AMD64 on both Debian 7 and Ubuntu 16.04.
We’ve been working hard on a new package build/publish pipeline, which can properly support multiple distributions, based on Jenkins Pipeline. This new packaging system also resolves longstanding issues such as “can’t really build anything except Mono” and “Architecture: All packages still get built on Jo’s laptop, with no public build logs”
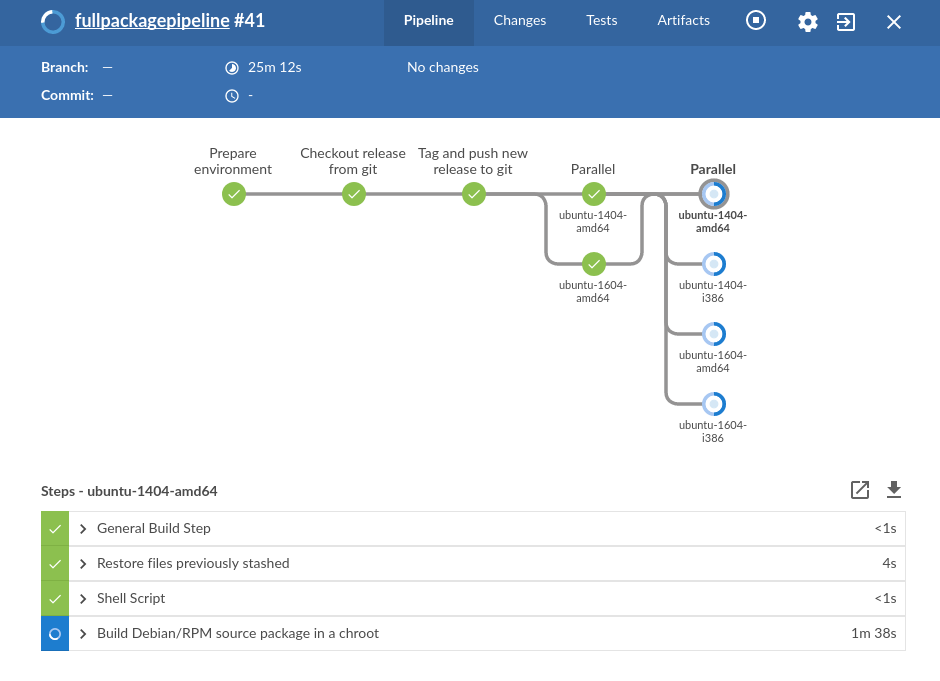
So, here’s the old build matrix:
| Distribution | Architectures |
|---|---|
| Debian 7 | ARM hard float, ARM soft float, ARM64 (actually Debian 8), AMD64, i386, PPC64el (actually Debian 8) |
| CentOS 7 | AMD64 |
And here’s the new one:
| Distribution | Architectures |
|---|---|
| Debian 7 | ARM hard float (v7), ARM soft float, AMD64, i386 |
| Debian 8 | ARM hard float (v7), ARM soft float, ARM64, AMD64, i386, PPC64el |
| Raspbian 8 | ARM hard float (v6) |
| Ubuntu 12.04 (*) | ARM hard float (v7), AMD64, i386 |
| Ubuntu 14.04 | ARM hard float (v7), ARM64, AMD64, i386, PPC64el |
| Ubuntu 16.04 | ARM hard float (v7), ARM64, AMD64, i386, PPC64el |
| CentOS 6 | AMD64, i386 |
| CentOS 7 | AMD64 |
The compatibility repositories will no longer be needed on recent Ubuntu or Debian – just use the right repository for your system. If your distribution isn’t listed… sorry, but we need to draw a line somewhere on support, and the distributions listed here are based on heavy analysis of our web server logs and bug requests.
You’ll want to change your package manager repositories to reflect your system more accurately, once Mono 5.0 is published (Update: Mono 5.0 is now live, please check out the new instructions on the download page).
We’re debating some kind of automated handling of this, but I’m loathe to touch users’ sources.list without their knowledge. CentOS builds are going to be late – I’ve been doing all my prototyping against the Debian builds, as I have better command of the tooling. Hopefully no worse than a week or two.
(*) this is mainly for Travis CI support which still uses Ubuntu 12.04 for now (despite it being EOL)