Note: This is a guest post by Calvin Buckley (@NattyNarwhal on GitHub) introducing the community port of Mono to IBM AIX and IBM i. If you’d like to help with this community port please contact the maintainers on Gitter.
You might have noticed this in the Mono 5.12 release notes, Mono now includes support for IBM AIX and IBM i; two very different yet (mostly!) compatible operating systems. This post should serve as an introduction to this port.
What does it take to port Mono?
Porting Mono to a new operating system is not as hard as you might think! Pretty much the entire world is POSIX compliant these days, and Mono is a large yet manageable codebase due to a low number of dependencies, use of plain C99, and an emphasis on portability. Most common processor architectures in use are supported by the code generator, though more obscure ISAs will have some caveats.
Pretty much all of the work you do will be twiddling #ifdefs to accommodate for
the target platform’s quirks; such as missing or different preprocessor
definitions and functions, adding the platform to definitions so it is
supported by core functionality, and occasionally having to tweak the runtime
or build system to handle when the system does something completely differently
than others. In the case of AIX and IBM i, I had to do all of these things.
Where would I be without IBM?
For some background on what needed to happen, we can start by giving some background on our target platforms.
Both of our targets run on 64-bit PowerPC processors in big endian mode. Mono does support PowerPC, and Bernhard Urban maintains it. What is odd about the calling conventions on AIX (shared occasionally by Linux) is the use of function descriptors, which means that pointers to functions do not point to code, but instead point to metadata about them. This can cause bugs in the JIT if you are not careful to consume or produce function descriptors instead of raw pointers when needed. Because the runtime is better tested on 64-bit PowerPC, and machines are fast enough that the extra overhead is not significant, we always build a 64-bit runtime.
In addition to a strange calling convention, AIX also has a different binary format - that means that currently, the ahead-of-time compiler does not work. While most Unix-like operating systems use ELF, AIX (and by extension, IBM i for the purposes of this port) use XCOFF, a subset of the Windows PE binary format.
AIX is a Unix (descended from the System V rather than the BSD side of the family) that runs on PowerPC systems. Despite being a Unix, it has some quirks of its own, that I will describe in this article.
Unix? What’s a Unix?
IBM i (formerly known as i5/OS or OS/400) is decidedly not a Unix. Unlike Unix, it has an object-based filesystem where all objects are mapped into a single humongous address space, backed on disk known as single level storage – real main storage (RAM) holds pages of objects “in use” and acts as a cache for objects that reside permanently on disk. Instead of flat files, IBM i uses database tables as the means to store data. (On IBM i, all files are database tables, and a file is just one of the “object types” supported by IBM i; others include libraries and programs.) Programs on IBM i are not simple native binaries, but instead are “encapsulated” objects that contain an intermediate form, called Machine Interface instructions, (similar to MSIL/CIL) that is then translated and optimized ahead-of-time for the native hardware (or upon first use); this also provides part of the security model and has allowed users to transition from custom CISC CPUs to enhanced PowerPC variants, without having to recompile their programs from the original source code.
This sounds similar to running inside of WebAssembly rather than any kind of Unix – So, then, how do you port programs dependent on POSIX? IBM i provides an environment called PASE (Portable Application Solutions Environment) that provides binary compatibility for AIX executables, for a large subset of the AIX ABI, within the IBM i. But Unix and IBM i are totally different; Unix has files and per-process address spaces, and IBM i normally does not, so how do you make these incongruent systems work?
To try to bridge the gap, IBM i also has an “Integrated File System” that supports byte-stream file objects in a true hierarchical file system directory hierarchy. For running Unix programs that expect their own address space, IBM i provides something called “teraspace” that provides a large private address space per process or job. This requires IBM i to completely changes the MMU mode and does a cache/TLB flush every time it enters and exits the Unix world, making system calls somewhat expensive; in particular, forking and I/O. While some system calls are not implemented, there are more than enough to port non-trivial AIX programs to the PASE environment, even with its quirks and performance limitations. You could even build them entirely inside of the PASE environment.
A port to the native IBM i environment outputting MI code with the ahead of time compiler has been considered, but would take a lot of work to write an MI backend for the JIT, use the native APIs in the runtime, and handle how the environment is different from anything else Mono runs on. As such, I instead PASE and AIX for the ease of porting existing POSIX compatible code.
What happened to port it?
The port came out of some IBM i users expressing an interest in wanting to run .NET programs on their systems. A friend of mine involved in the IBM i community had noticed I was working on a (mostly complete, but not fully working) Haiku port, and approached me to see if it could be done. Considering that that I now had experience with porting Mono to new platforms, and there was already a PowerPC JIT, I decided to take the challenge.
The primary porting target was IBM i, with AIX support being a by-product. Starting by building on IBM i, I set up a chroot environment to work in, (chroot support was added to PASE fairly recently), setting up a toolchain with AIX packages. Initial bring-up of the port happened on IBM i, up to the point where the runtime was built, but execution of generated code was not happening. One problem with building on IBM i, however, is that the performance limitations really start to show. While building took the same amount of time on the system I had access to (dual POWER6, taking about roughly 30 minutes to build the runtime) as AIX due to it mostly being computation, the configure script was extremely impacted due to its emphasis on many small reads and writes with lots of forking. Whereas it took AIX 5 minutes and Linux 2 minutes to run through the configure script, it took IBM i well over an hour to run through all of it. (Ouch!)
At this point, I submitted the initial branch as a pull request for review. A lot of back and forth went on to work on the underlying bugs as well as following proper style and practices for Mono. I set up an AIX VM on the machine, and switched to cross-compiling from AIX to IBM i; targeting both platforms with the same source and binary. Because I was not building on IBM i any longer, I had to periodically copy binaries over to IBM i, to check if Mono was using missing libc functions or system calls, or if I had tripped on some behaviour that PASE exhibits differently from AIX. With the improved iteration time, I could start working on the actual porting work much more quickly.
To help with matters where I was unsure exactly how AIX worked, David Edelsohn from IBM helped by explaining how AIX handles things like calling conventions, libraries, issues with GCC, and best practices for dealing with porting things to AIX.
What needed to change?
There are some unique aspects of AIX and the subset that PASE provides, beyond
the usual #ifdef handling.
What did we start with?
One annoyance I had was how poor the GNU tools are on AIX. GNU binutils are effectively useless on AIX, so I had to explicitly use IBM’s binutils, and deal with some small problems related to autotools with environment variables and assumption of GNU ld features in makefiles. I had also dealt with some issues in older versions of GCC (which is actually fairly well supported on AIX, all things considered) that made me upgrade to a newer version. However, GCC’s “fixincludes” tool to try to mend GCC compatibility issues in system header files in fact mangled them, causing them to be missing some definitions found in libraries. (Sometimes they were in libc, but never defined in the headers in the first place!)
Improper use of function pointers was sometimes a problem. Based on the advice
of Bernhard, there was a problem with the function descriptors #ifdefs, which
had caused a mix-up interpreting function pointers as code. Once that had been
fixed, Mono was running generated code on AIX for the first time – quite a
sight to behold!
What’s a “naidnE?”
One particularly nerve-racking issue that bugged me while trying to bootstrap was with the Decimal type returning a completely bogus value when dividing, causing a non-sense overflow condition. Because of constant inlining, this occurred when building the BCL, so it was hard to put off. With some careful debugging from my friend, comparing the variable state between x86 and PPC when dividing a decimal, we had determined exactly where the incorrect endianness handling had taken place and I had came up with a fix.
While Mono has historically handled different endianness just fine, Mono has started to replace portions of its own home-grown BCL with CoreFX, (the open-source Microsoft BCL) and it did not have the same rigor towards endianness issues. Mono does patch CoreFX code, but it sometimes pulls in new code that has not had endianness (or other such possible compatibility issues) worked out yet and thus requires further patching. In this case, the code had already been fixed for big endian before, but pulling in updated code from CoreFX had created a new problem with endianness.
What’s “RTLD_MEMBER?”
On AIX, there are two ways to handle libraries. One is your typical System V style linking with .so libraries; this isn’t used by default, but can be forced. The other way is the “native” way to do it, where objects are stored in an archive (.a) typically used for holding objects used for static linking. Because AIX always uses position-independent code, multiple objects are combined into a single object and then inserted into the archive. You can then access the library like normal. Using this technique, you can even fit multiple shared objects of the same version into a single archive! This took only minimal changes to support; I only had to adjust the dynamic library loader to tell it to look inside of archive files, and some build system tweaks to point it to the proper archive and objects to look for. (Annoyingly, we have to hardcode some version names of library objects. Even then, the build system still needs revision for cases when it assumes that library names are just the name and an extension.)
What’s “undefined behaviour?”
When Mono tries to access an object reference, and the reference (a pointer) is null, (that is, zero) Mono does not normally check to see if the pointer is null. On most operating systems, when a process accesses invalid memory such as a null pointer, it sends the process a signal (such as SIGSEGV) and if the program does not handle that signal, it will terminate the program. Normally, Mono registers a signal handler, and instead of checking for null, it would just try to dereference a null pointer anyways to let the signal handler interrupt and return an exception to managed code instead. AIX doesn’t do that – it lets programs dereference null pointers anyway! What gives?
Accessing memory via a null pointer is not actually defined by the ANSI C standards – this is a case of a dreaded undefined behaviour. Mono relied on the assumption that most operating systems did it in the typical way of sending a signal to the process. What AIX instead does is to implement a “null page” mapped at 0x0 and accepts reads and writes to it. (You could also execute from it, but since all zeroes is an invalid opcode on PowerPC, this does not do much but throw an illegal instruction signal at the process.) This is a historical decision, relating back to code optimizations implemented in older IBM compilers made where they used speculative execution in compiler-generated code during the 1980s for improved performance when evaluating complex logical expressions. Because we cannot rely on handling a signal to catch the null dereference, we can instead force the behaviour to always check if pointers are null, (normally reserved for runtime debugging) to be on all the time.
What’s so boring about TLS?
BoringSSL is required to get modern TLS required by newer websites. The build system, instead of autotools and make, is CMake based. Luckily, this worked fine on AIX, though I had to apply some massaging for it to do 64-bit library mangling. For a while, I was stumped by an illegal instruction error, that turned out to be due to not linking in pthread to the library, and it not warning about it.
It turns out that even though BoringSSL was now working, one cipher suite (secp256r1) was not, so sites using that cipher were broken. To try to test it, I had gone “yak shaving” to build what was needed for the test harness according to the README; Ninja and Go. I had a heck of a time trying to build Go on a PPC Linux system to triage, but as it turned out, I did not actually need it anyway – Mono had tweaked the build system so that it was not needed after all; I just had to flip a CMake flag to let it build the tests and run them manually. After figuring out what exactly was wrong, it turned out to be an endianness issue in an optimized path. A fix was attempted for it, but in the end, only disabling it worked and let the cipher run fine on big endian PowerPC. Since the code came from Google code that has been rewritten in both BoringSSL and OpenSSL upstream’s latest sources, it is due to be replaced the next time Mono’s BoringSSL fork gets updated.
What else?
I had an issue with I/O getting some spurious and strange issues with
threading. Threads would complain that they had an unexpected errno of 0.
(indicating success) What happened was that AIX does not assume that all
programs are thread-safe by default, so errno was not thread-local. One small
#define later, and that was fixed. (Miguel de Icaza was amused that some
operating systems still consider thread safety to be an advanced feature. 🙂)
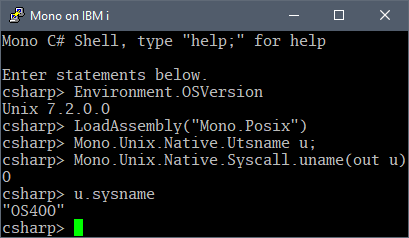
We also found a cosmetic issue with uname. Most Unices put their version in the
release field of the uname structure, and things like the kernel type in the
version field. AIX and PASE however, put the major version in the version field,
and the minor version in the release field. A simple sprintf for the AIX case
was enough to fix this.
PASE has many quirks – this necessitated some patches to work around deficiencies; from bugs to unimplemented functions. I aim to target IBM i 7.1 or newer, so I worked around some bugs that have been fixed in newer versions. A lot of this I cleaned up with some more preprocessor definitions.
What’s next?
Now that Mono runs on these platforms, there’s still a lot of work left to be done. The ahead of time compiler needs to be reworked to emit XCOFF-compatible code, libgdiplus needs to be ported, Roslyn is broken on ppc64be, continuous integration would be useful to detect build failures, the build system is still a bit weird regarding AIX libraries, and plenty more where that came from. Despite all this, the fact the port works well enough already in its current state should provide a solid foundation to work with, going forward.